Flink: Savepoint 和 Checkpoint 的 3 个不同点-转
— flink — 1 min read
原文:differences-between-savepoints-and-checkpoints-in-flink 作者:Stefan Richter, Dawid Wysakowicz, Markos Sfikas 译者:云邪(Jark)
在本文中,我们将阐述 Savepoint 和 Checkpoint 是什么,它们主要用在什么时候,以及对比它们的主要区别。
什么是 Savepoint 和 Checkpoint
Savepoint 是用来为整个流应用程序在某个“时间点”(point-in-time)的生成快照的功能。该快照包含了输入源的位置信息,数据源读取到的偏移量(offset),以及整个应用的状态。借助 Chandy-Lamport 算法的变体,我们可以无需停止应用程序而得到一致的快照。Savepoint 包含了两个主要元素:
首先,Savepoint 包含了一个目录,其中包含(通常很大的)二进制文件,这些文件表示了整个流应用在 Checkpoint/Savepoint 时的状态。 以及一个(相对较小的)元数据文件,包含了指向 Savapoint 各个文件的指针,并存储在所选的分布式文件系统或数据存储中。 上述有关 Savepoint 的介绍听起来和之前文章中介绍的 Checkpoint 很像。Checkpoint 是 Flink 用来从故障中恢复的机制,快照下了整个应用程序的状态,当然也包括输入源读取到的位点。如果发生故障,Flink 将通过从 Checkpoint 加载应用程序状态并从恢复的读取位点继续应用程序的处理,就像什么事情都没发生一样。
可以阅读之前 Flink 小贴士的一篇关于 Flink 如何管理 Kafka 消费位点的文章。
Savepoint 和 Checkpoint 的 3 个不同点
Savepoint 和 Checkpoint 是 Apache Flink 作为流处理框架非常独特的两个特性。Savepoint 和 Checkpoint 在实现中看起来也很相似,但是,这两个功能主要有以下3个不同点:
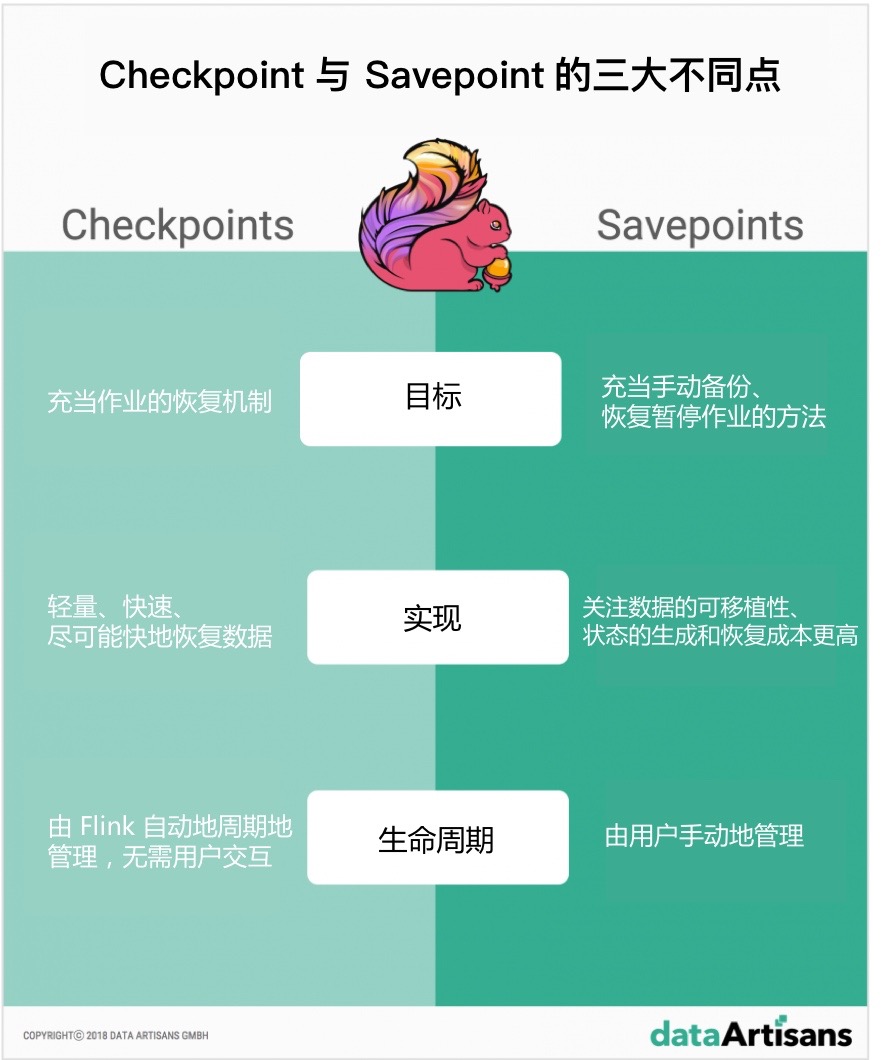
目标: 从概念上讲,Flink 的 Savepoint 和 Checkpoint 的不同之处很像传统数据库中备份与恢复日志之间的区别。Checkpoint 的主要目标是充当 Flink 中的恢复机制,确保能从潜在的故障中恢复。相反,Savepoint 的主要目标是充当手动备份、恢复暂停作业的方法。
实现: Checkpoint 和 Savepoint 在实现上也有不同。Checkpoint被设计成轻量和快速的机制。它们可能(但不一定必须)利用底层状态后端的不同功能尽可能快速地恢复数据。例如,基于 RocksDB 状态后端的增量检查点,能够加速 RocksDB 的 checkpoint 过程,这使得 checkpoint 机制变得更加轻量。相反,Savepoint 旨在更多地关注数据的可移植性,并支持对作业做任何更改而状态能保持兼容,这使得生成和恢复的成本更高。
生命周期: Checkpoint 是自动和定期的,它们由 Flink 自动地周期性地创建和删除,无需用户的交互。相反,Savepoint 是由用户手动地管理(调度、创建、删除)的。
何时使用 Savepoint ?
虽然流式应用程序处理的数据是持续地生成的(“运动中”的数据),但是存在着想要重新处理之前已经处理过的数据的情况。Savepoint 可以在以下情况下使用:
- 部署流应用的一个新版本,包括新功能、BUG 修复、或者一个更好的机器学习模型
- 引入 A/B 测试,使用相同的源数据测试程序的不同版本,从同一时间点开始测试而不牺牲先前的状态
- 在需要更多资源时扩容应用程序
- 迁移流应用程序到 Flink 的新版本上,或者迁移到另一个集群
结论
Checkpoint 和 Savepoint 是 Flink 中两个不同的功能,它们满足了不同的需求,以确保一致性、容错性,和满足作业升级、BUG 修复、迁移、A/B测试等。这两个功能相结合,可以确保应用程序的状态在不同的场景和环境中保持不变。