Flink:反压 Back Pressure
— flink — 1 min read
什么是网络流控
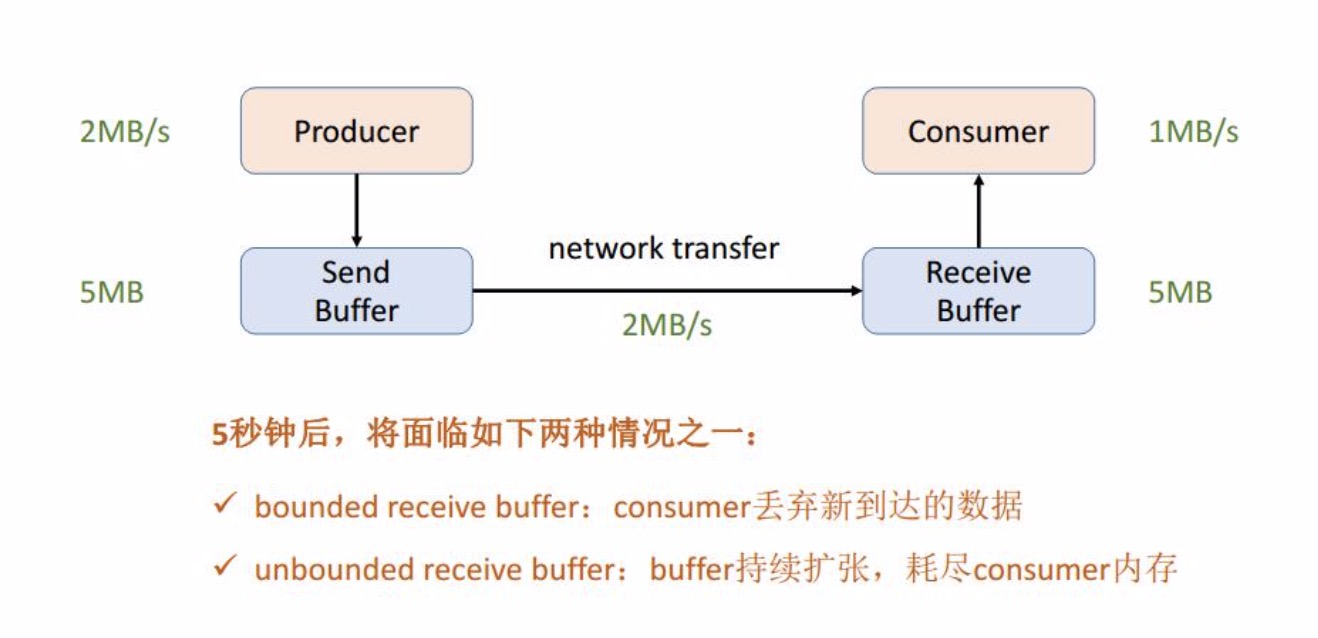
在分析flink反压机制之前先理解一下网络流控机制,上图中生产者的吞吐率是2m/s,生产者与消费者之前的传输速率也是2m/s,也就是生产者实时产生的数据都将会被发送的消费者端,不过此时消费者的吞吐率只有1m/s,这样就会在消费者的buffer进行缓存处理,不过在5s后buffer将会 被打满,此时将会面临两种情况:
- 如果 Receive Buffer 的内存规划是有界的,也就是不能无限申请新的内存用来满足buffer新的需要,那么新到的消息将会被抛弃。
- 如果 Receive Buffer 的内存规划是无界的,可以继续向系统申请新的内存用来保存消息,不过过不了多久内存也将会被耗尽。
所以为了解决上下游吞吐率不匹配,导致的消息丢失或者内存溢出的问题,人们想到了使用限流的方式进行平衡,也就是说在消费者过慢时减小生产者的生产速率,在消费者空闲时提升生产者胜场速率。总体来说对流量的控制也就是限流分为两种。静态限流、动态限流。
静态限流
所谓静态限流,就是在生产和消费前对整体(生产者、消费者、网络io)性能进行评估,在生产者端设定一个固定的速率比如1m/s,此后不论生产者如何变更,那么发送到网络中知道消费者收到的速率都不会高于1m/s,这样就不会导致消费者端和生产者端吞吐率不一致的问题。不过静态限流也有较为明显的缺点。
- 前期对整体进行评估时无法准确的估计出整体性能,也就是说不发准确找到到底那里是整体的瓶颈。
- 在开始发送后消费者的吞吐率还是会不断变化的,也就是说他可能高于1m/s,此时一定情况就会产生性能浪费,也有可能会低于1m/s也就是说还存在消费积压的问题。无法灵活应对两端出现的速率变化。
动态流控
动态流控主要是为了解决静态流控出现的问题,在当前方案上通过消费者实时向生产者反馈信息,从而调整生产者的速率。
- 当消费者产生消息积压时,发送反馈告知生产者降低生产速率。
- 当消费者处理能力剩余时,发送反馈告知生产者适当提高生产速率。
flink中的反压
flink是一款优秀的流式计算引擎,也就意味着他也要面对在pipline中某一个节点称为性能瓶颈,如何解决这个问题从而缓解单个节点对整个处理任务的影响。在flink1.5之前才用的是基于TCP-based(基于TCP的流量控制)的反压机制,这里不在过多介绍,关于TCP的流量控制可查看网络:运输层TCP-流量控制。
1基于TCP的反压有什么缺点呢?2> 1. 在发生反压时将会通过层层反馈的机制由下游一致反馈到上游,这一过程较为漫长。3> 2. 在一个TaskManager中同时运行了多个Task而当其中一个task产生反压时,将会暂停netty和Socket的工作,对其他的工作都会产生影响,比如checkpoint等机制。本文主要记录Since flink1.5以后的版本基于Credit-based的反压机制,flink runtime中主要由operator和stream两大组件。每一个operator会基于当前的stream上进行操作,生成一个新的stream,下图中producer operator基于当前流入进来的stream生成新的stream,并准备流入下一个operator。这一过程中就涉及到了flink的反压机制。在flink采用了高效且有界的分布式阻塞队列实现反压,通过队列的容量来模拟TCP流控中的接收窗口实现动态反压调节。
在flink中,这些分布式阻塞队列就是这些逻辑流,而队列容量是通过缓冲池(LocalBufferPool)来实现的。每个被生产和被消费的流都会被分配一个缓冲池。缓冲池管理着一组缓冲(Buffer),缓冲在被消费后可以被回收循环利用。同时参照TCP的窗口流控机制,在InputGate 和 ResultPartition之间建立通信,每次由接收方响发送方反馈当前可用容量,发送方这根据当前可用容量进行动态调整发送数据的大小。
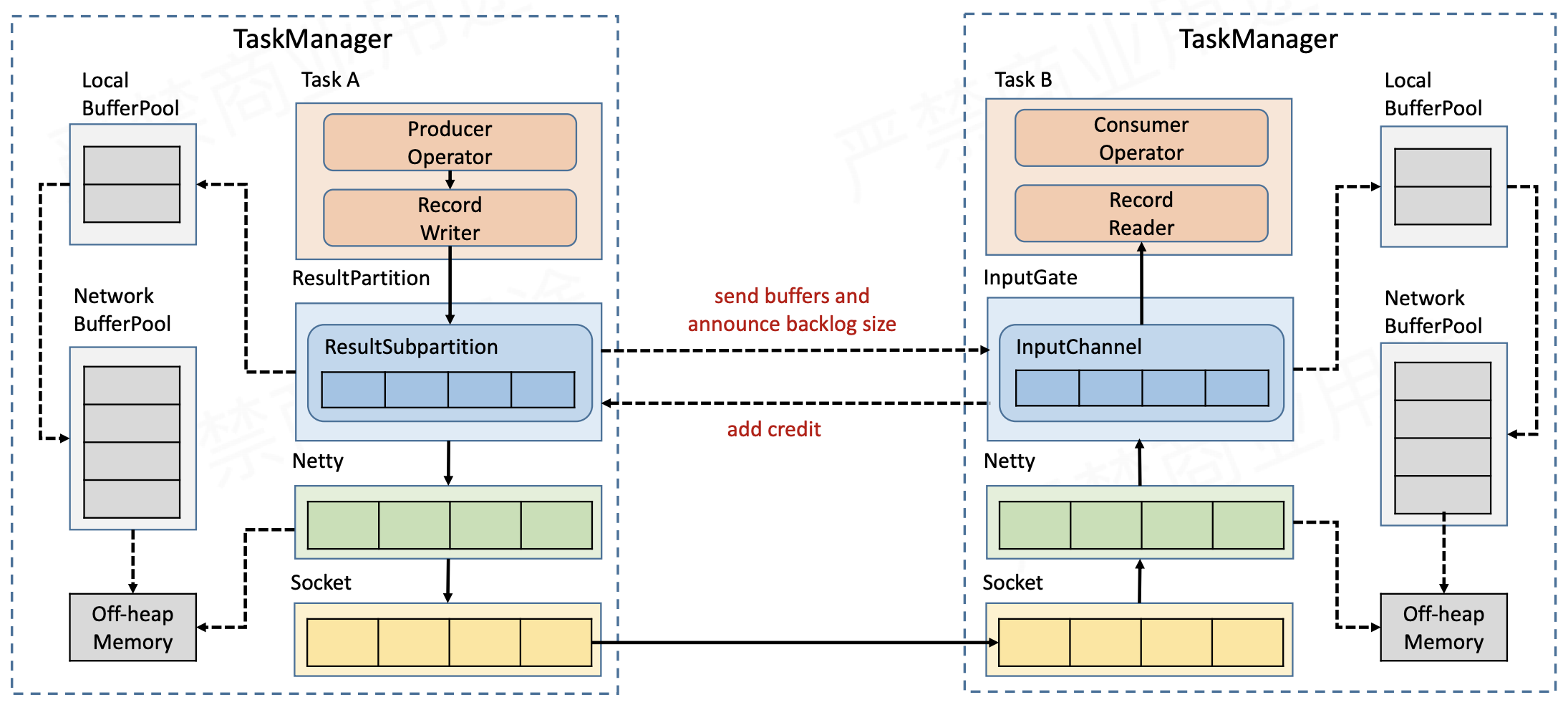
flink流的网络传输
简单了解flink的反压模型后,详细分析一下flink流的网络传输,我们知道在flink中每一个流source task开始之后流经每一个task,经过转换操作后生成新的流继续流动,具体的流程借助上图来具体分析:
- 此时Task Manager启动,先初始化一个NetworkEnvironment对象,用来管理网络相关对象,包括图中的Netty和NetworkBufferPool等相关对象及空间,同时在NetworkBufferPool内部会生成一定数量的内存块,用来给每一个task分配使用。每一个TaskManager只会有一个NetworkBufferPool。
- 图中两个Task只提到了InputGate(IG)或 ResultPartition(RP),其实每一个Task启动后都会包含一个IG和RP,一个用来接收数据每一个用来发送数据,两个的底层都是基于Netty和Socket进行通信的,也就是说在下一层都是通用的。并且NetworkEnvironment会为其在NetworkBufferPool处申请一定的资源我们管他叫做LocalBufferPool,这个LocalBufferPool生命周期是和Task同步的,一同被创建和销毁。
- 在Task运行过程中,RecordWriter将新的流写入到ResultPartition,准备通过Netty到Socket发送出去,下一个Task,Task B同样通过Socket到Netty接收到数据准备写入InputGate,写入之前会向其拥有的LocalBufferPool申请空间,若已没有且存在还没达到申请上限(出现这种情况的原因是flink的内存模型影响,会动态扩容),则会向NetworkBufferPool申请并交给LocalBufferPool。
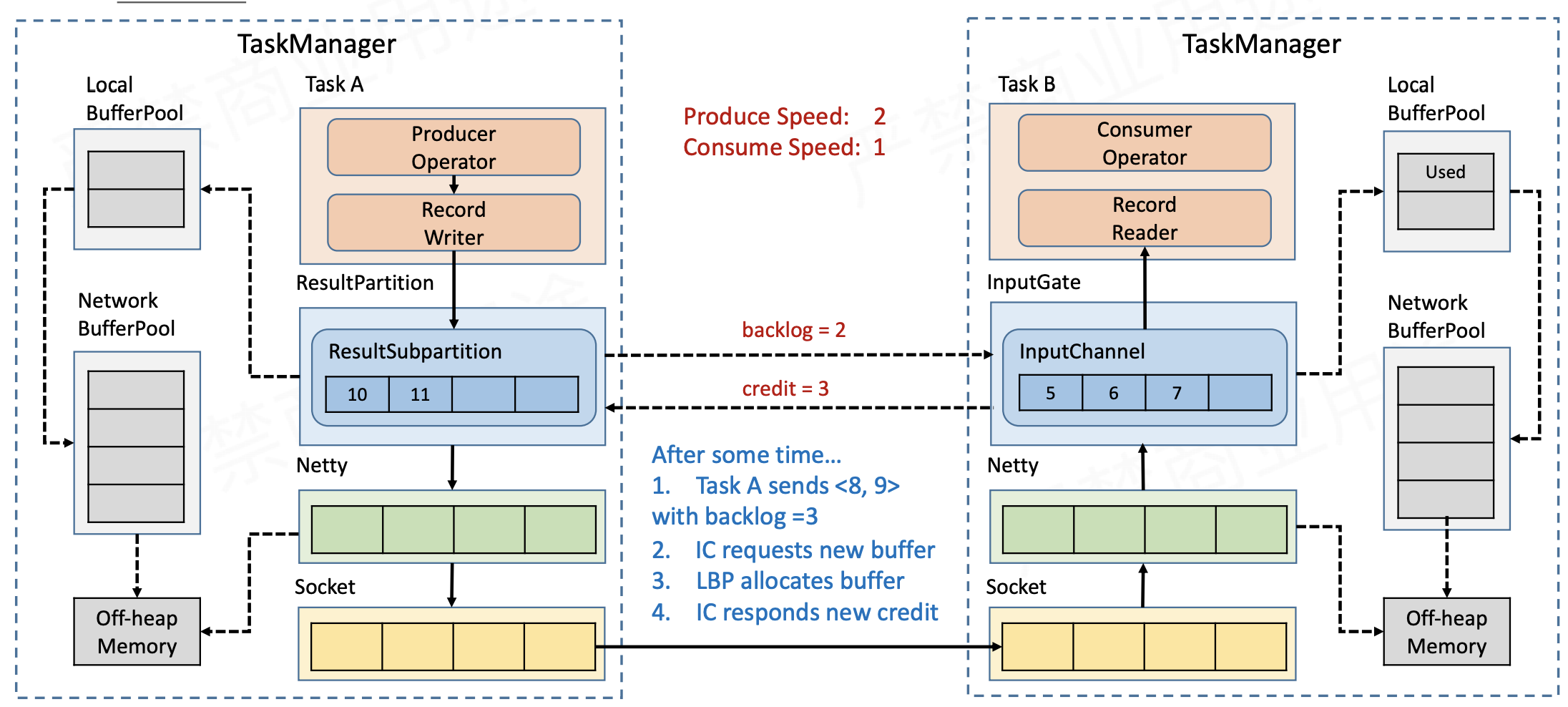
- 同时每一次 ResultSubPartition 向 InputChannel 发送消息的时候都会发送一个 backlog size 告诉下游准备发送多少消息,下游就会去计算有多少的 Buffer 去接收消息,算完之后如果有充足的 Buffer 就会返还给上游一个 Credit 告知他可以发送消息(图上两个 ResultSubPartition 和 InputChannel 之间是虚线是因为最终还是要通过 Netty 和 Socket 去通信)
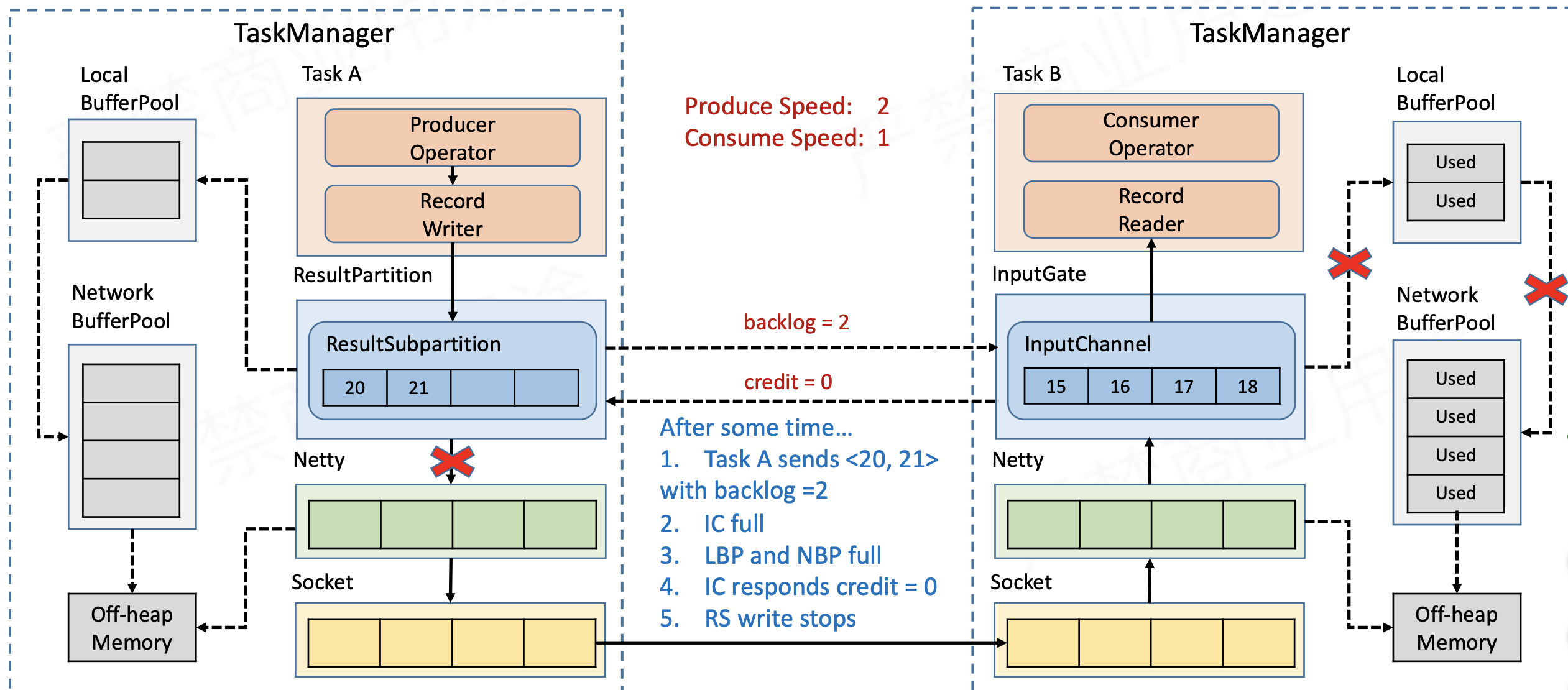
- 若NetworkBufferPool中没有足够的空间提供给LocalBufferPool呢?也就是下边这种情况,接收端所有空间都被占满。此时就下游在上游发送数据之前就会告知上游 Credit = 0,ResultSubPartition 接收到之后就不会向 Netty 去传输数据,上游 TaskManager 的 Buffer 也很快耗尽,达到反压的效果,这样在 ResultSubPartition 层就能感知到反压,不用通过 Socket 和 Netty 一层层地向上反馈,降低了反压生效的延迟。同时也不会将 Socket 去阻塞,解决了由于一个 Task 反压导致 TaskManager 和 TaskManager 之间的 Socket 阻塞的问题。
- 同样,flink采用了和TCP一样的0 credit探测机制,当credit=0时,会定时向下游发送探测信息,用来保证能够及时的获取到下游buffer的最新信息,一遍能够及时的恢复发送。
总结
本篇详细记录了flink反压机制的相关原理,通过分析网络流控我们知道静态流控和动态流控的区别,以及为什么要在flink中使用动态流控,也就是反压机制,通过反压机制解决了flink短时间内上游task生产过快,下游来不及消费的吞吐率不均衡问题。同时通过对比基于TCP的反压机制,我们知道基于Credit-based的反压机制解决了TCP反压的延迟问题和Socket阻塞问题,并了解到其实Credit-based是采用了模拟TCP滑动窗口的流控机制进行反压。
over~